smalltalk-from-scratch — Part 2
The Compiler That Couldn't Run Its Own Output
To build a Smalltalk-80 VM you need a compiler. But Smalltalk bytecode is useless without a running Smalltalk. The escape: a JSON intermediate representation and an empirically-discovered grammar.
Part 2 of 7. Part 1 covered the Smalltalk-80 object model and what makes it unusual. This part covers the first concrete problem: how do you compile Smalltalk-80 when you don’t have a Smalltalk-80 to compile it with?
The first problem in building a Smalltalk-80 implementation is a classic bootstrap trap, and it catches you before you’ve written a single line of interesting code.
The goal is to produce, from the Blue Book’s Part IV source code, a running Smalltalk-80 system. A running system requires a heap full of objects: every class, every method, every compiled bytecode, every global variable, all allocated and linked correctly in memory. To get compiled bytecode, you need a compiler. The question is: what does the compiler output?
In a typical language implementation, you’d compile source code to native machine code or to a well-defined bytecode that a separate VM executes. But Smalltalk bytecode isn’t like x86 machine code. It isn’t self-contained. A Smalltalk method’s bytecode makes constant reference to the surrounding object memory: the receiver’s class, the method’s literal frame (which contains symbols, string literals, and class references), the global dictionary, the process scheduler. A compiled Smalltalk method is not a standalone binary — it’s an object that only makes sense inside a running Smalltalk heap.
So you can compile Smalltalk source to bytecode. But you can’t run that bytecode until you have a complete Smalltalk system already running. And to have a running system, you need the bytecode. This is the Catch-22.
The Way Out
The escape route I chose was to change what the compiler produces.
Instead of emitting bytecode ready to be loaded into a Smalltalk heap, the compiler emits a complete structural description of every class in the source file. For each class, this description includes everything you’d need to reconstruct that class in a heap from scratch: its name, its superclass name, its metaclass name, the metaclass’s superclass, all instance variable names, all class variable names, any pool dictionary references, every instance method, every class method, and for each method: the selector, the primitive number if any, the argument names, the temporary variable names, the literal frame contents, and the compiled bytecode as an array of integers.
This description is emitted as JSON. Not because JSON is an especially elegant format for this problem, but because it’s universally readable, easy to inspect and debug, and straightforward to parse from C#.
The key insight is that this JSON is not Smalltalk bytecode running in a heap. It’s a blueprint. A separate program — the cold-start loader — reads the blueprint and builds the heap. The compiler never needs to run inside a Smalltalk environment. It just needs to understand Smalltalk source code well enough to extract complete structural information from it.

The JSON file has a top-level structure that deduplicates strings globally:
{
"metadata": {
"version": "1.0.9",
"generator": "Smalltalk.Compiler v0.0.0.0",
"generatedAt": "2026-02-13T02:37:20Z",
"classCount": 530,
"methodCount": 5310,
"initExpressionCount": 274
},
"symbols": ["!", "%", "&", "*", "+", "...", "asPoint", "...", "x", "y"],
"strings": ["...", "Answer the x coordinate.", "..."],
"classes": [ ... ],
"methods": [ ... ],
"initExpressions": [ ... ]
}Rather than embedding class names and selector strings inline in every record, the file has a global symbols array and a global strings array. Every name in the file is an integer index into one of these arrays. The cold-start loader resolves the indices at load time. A 530-class, 5,310-method system has a lot of repeated symbol names — initialize, printOn:, at:put: appear in dozens of classes. The global table means each name appears once regardless of how many methods reference it.
A class record looks like this (Point, simplified):
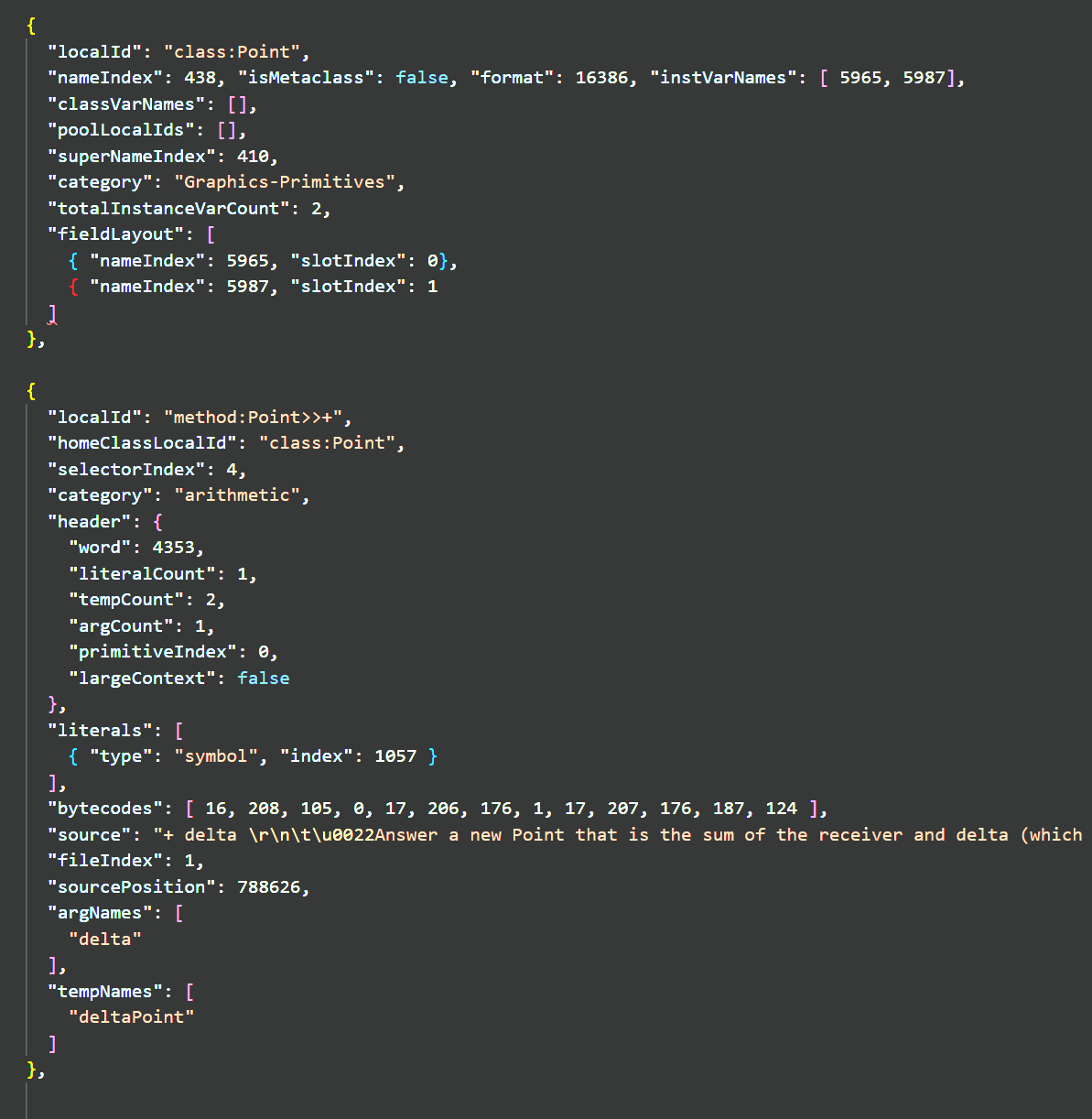
{
"localId": "class:Point",
"nameIndex": 438,
"isMetaclass": false,
"instVarNames": [5965, 5987],
"classVarNames": [],
"superNameIndex": 410,
"category": "Graphics-Primitives",
"totalInstanceVarCount": 2
}symbols[438] is "Point". symbols[410] is "Object". symbols[5965] is "x". symbols[5987] is "y". The corresponding metaclass record has "localId": "meta:Point" and "isMetaclass": true.
Methods are stored in a flat array at the top level, each referencing its class by localId:
{
"localId": "method:Point>>x",
"homeClassLocalId": "class:Point",
"selectorIndex": 5965,
"header": {
"primitiveIndex": 0,
"argCount": 0,
"tempCount": 0,
"literalCount": 0
},
"literals": [],
"bytecodes": [0, 124],
"source": "x\r\n\t\"Answer the x coordinate.\"\r\n\t^x",
"argNames": [],
"tempNames": []
}Bytecode 0 is “push receiver variable 0” (the first instance variable, x). Bytecode 124 is “return top of stack.” The source text is stored alongside the bytecodes — not used by the cold-start loader, but invaluable for debugging when a method misbehaves and you need to know what it was supposed to do.
The + method is more interesting:
{
"localId": "method:Point>>+",
"homeClassLocalId": "class:Point",
"selectorIndex": 4,
"header": {
"primitiveIndex": 0,
"argCount": 1,
"tempCount": 2,
"literalCount": 1
},
"literals": [{ "type": "symbol", "index": 1057 }],
"bytecodes": [16, 208, 105, 0, 17, 206, 176, 1, 17, 207, 176, 187, 124],
"source": "+ delta\r\n\t| deltaPoint |\r\n\tdeltaPoint := delta asPoint.\r\n\t^x + deltaPoint x @ (y + deltaPoint y)"
}The literal at index 1057 is "asPoint" — the message sent to normalize the argument to a Point. The bytecodes push delta, send asPoint, store the result in deltaPoint, then compute x + deltaPoint x @ (y + deltaPoint y) — two additions and the @ Point constructor.
Primitive methods look slightly different. SmallInteger >> + has a non-zero primitiveIndex:
{
"localId": "method:SmallInteger>>+",
"homeClassLocalId": "class:SmallInteger",
"selectorIndex": 4,
"header": { "primitiveIndex": 1, "argCount": 1, "tempCount": 0, "literalCount": 0 },
"literals": [],
"bytecodes": [112, 16, 133, 32, 124],
"source": "+ aNumber\r\n\t<primitive: 1>\r\n\t^super + aNumber"
}The bytecode breakdown: 112 pushes self, 16 pushes the argument, 133 32 sends + to super, 124 returns. These bytecodes are the Smalltalk fallback path — they only execute if the primitive fails.
The original 1983 source file uses over a hundred distinct primitive numbers. The compiler needed to extract all of them correctly — <primitive: 1> for SmallInteger addition, <primitive: 96> for BitBlt’s copyBits, <primitive: 102> for DisplayScreen>>beDisplay, and many others. Getting primitive number extraction right was essential: a primitive number mismatch means the VM calls the wrong C# method, silently.
The init expressions are collected at the top level too:
{
"localId": "init:202",
"source": "Symbol initialize",
"bytecodes": [ ... ],
"literals": [ ... ]
}274 of them in this build — class comments, initialize calls, global variable setup, and infrastructure construction. They have the same bytecode/literal structure as methods, because the compiler compiles them with the same machinery; they just have no home class.
That’s the shape of it. Here is what the actual JSON looks like — the Point class record and Point>>+ method record from the compiled output:
Now I had to build a compiler that could produce it.
The Grammar Problem
To compile Smalltalk, you need a grammar. The Blue Book provides one in Part I. I read it carefully, spent roughly two months writing an ANTLR4 grammar and repeatedly running the file-out source through it — no code generator yet, just a parser and the AST that ANTLR4 would build — and immediately found that the Blue Book’s grammar was incomplete. That two-month period has no commit history. It preceded the repository: just a grammar file being iteratively edited, parse failures diagnosed by eye against ANTLR error output, no automated test harness. The June 2025 commits represent the point where the parser became useful enough to commit.
Not wrong — incomplete. The Blue Book describes the Smalltalk-80 language correctly, as far as it goes. But the source code in Part IV contains constructs that Part I simply doesn’t mention.
My approach was empirical. I had one corpus: 41,400 lines of authentic Smalltalk-80 source code, the file-out distributed with historical Smalltalk-80 implementations. There are no other complete Smalltalk-80 sources available. There are snippets online and in other books, but they’re either incomplete or they’re from later Smalltalk variants — Pharo, Squeak, VisualWorks — that extended the language beyond the 1983 standard.
The method was: write a grammar rule based on the Blue Book, run the full source file through it, observe every parse failure, inspect the offending code, figure out what the grammar needed to handle it, extend the grammar, and repeat. Each failure was evidence of a construct the Blue Book had not described. The source file was simultaneously my test suite and my specification.
This refinement process — now with the code generator in the loop, producing JSON that could be checked for correctness — ran through June and July of 2025. The commit history from those weeks reads like a field notebook: "Allow cascaded keyword messages without receiver". "Add ampersand and pipe operators to grammar". "Add AST support for expression chunks and new literals". "Allow empty statements". Each entry represents a construct the source file contained that the grammar still didn’t handle correctly — constructs that had been patched around or deferred during the pre-commit phase and now needed to be properly resolved with the code generator exposing them.
Between July 14th and August 3rd, almost nothing was committed. Three weeks of near silence in the commit log. This happens in real projects and it deserves an honest account: I was thinking. The grammar was mostly working but there were a handful of stubborn cases I couldn’t resolve by staring at them. The approach of mechanically extending the grammar rule by rule was hitting a wall. I needed to step back and understand the full shape of the Smalltalk-80 expression grammar more carefully.
Smalltalk’s grammar is deceptively tricky because of its message precedence rules. Unary messages have highest precedence, binary messages next, keyword messages lowest. This is clean and elegant in the language but it produces a grammar that doesn’t factor cleanly into ANTLR4’s LL(k) parsing model without some care. Cascades — where you send multiple messages to the same receiver with ; — interact with this in ways the Blue Book underspecifies.
The mulling produced the approach that finally made everything fall into place. I don’t have a more dramatic account than that: sometimes the problem just needs time.
On August 3rd, the last test passed. The grammar parsed all 41,400 lines cleanly, with no errors.

What ANTLR4 Buys You
The grammar is implemented in ANTLR4, a widely-used parser generator. Writing the grammar in ANTLR4 rather than a hand-rolled recursive descent parser was a deliberate choice: ANTLR generates good error messages, supports left-factoring and lookahead automatically, and produces a parse tree that can be walked by a visitor.
The ANTLR4 toolchain produces a parser and a base visitor class from the grammar file. I wrote an AST builder visitor that walks the parse tree and produces an abstract syntax tree suitable for the next stage. A separate compiler visitor walks the AST and produces the JSON output.
The AST pass was necessary because parse trees and ASTs serve different purposes. A parse tree reflects the grammar’s structure, including all the disambiguation rules and helper productions that make ANTLR happy. An AST reflects the program’s semantic structure. A BinaryMessageExpression AST node says “send this binary message to this receiver with this argument.” The corresponding parse tree node might span several grammar rules and intermediate nodes that don’t map to anything meaningful in the program.
The Aug 4 commits document several follow-on discoveries after the initial breakthrough: AST null reference issues, metaclass support for class methods, handling of class-side vs. instance-side method definitions. These aren’t grammar problems — the parser was clean — but semantic problems in the AST builder. Cascade messages where the compiler needed to generate dup bytecodes; blocks in method position that required a different context than blocks in expression position; class methods that needed to be compiled against the metaclass’s variable scope rather than the class’s.
The Epistemic Problem
There is something honest I should say about this process.
The grammar I produced is the grammar that handles everything in that one source file. It almost certainly handles everything in the real Smalltalk-80 language — the source file is a fairly complete representation of the system. But I can’t be certain it handles every valid Smalltalk-80 construct, because I only validated it against the thing I used to build it. It’s the linguistic equivalent of checking your translation by re-reading the original.
If there are valid Smalltalk-80 programs that use constructs not present in that source file, my grammar might reject them. I don’t know of any such programs — the source file is the entire Smalltalk-80 class library — but I can’t rule it out.
This is a known limitation of corpus-driven grammar induction. I mention it not to apologize for it but because it affects how the compiler should be understood: as a tool built to handle one specific, important corpus, rather than as an implementation of a formally-specified language. The distinction matters if you ever want to extend it.
Over time, as the system developed, I did adopt some selectors and constructs from modern Smalltalk variants — things like ifEmpty:, ensure:, and := as an alias for the assignment arrow. These were deliberate additions, imported for practical value. They’re not in the original grammar; they extend it. That’s a different thing from the original grammar being incomplete.
The practical consequence of corpus-driven discovery is that the process doesn’t always move forward steadily — and that’s what happened next.
What the Compiler Knows
Once the grammar was complete and the compiler was producing JSON, the next question was whether the JSON was correct. Not syntactically correct — that’s easy to verify — but semantically correct. Does the bytecode in each method’s array actually represent what the Smalltalk source says?
The Smalltalk-80 bytecode set is documented in Part III of the Blue Book, and it is specific. There are exactly 256 possible bytecodes. Some are single-byte instructions (push receiver, push nil, return self). Some are two-byte forms with an extended operand. The operand ranges and encodings are all specified. Getting them right matters because the interpreter I haven’t built yet will depend on them.
The approach was to write extensive tests for the compiler output before building the interpreter. For each class of bytecode — push instructions, store instructions, message sends, jumps, returns — I wrote test methods in Smalltalk, compiled them, and verified the resulting bytecode arrays against what the Blue Book said they should be.
This revealed several bugs. The most significant was in how branch offsets were calculated for conditional jumps. Smalltalk-80 uses PC-relative branch offsets, and the calculation of “how many bytes to jump forward” is based on the position of the instruction after the branch, not the branch instruction itself. Getting this wrong by one byte means every ifTrue: and ifFalse: in the system is broken — which is most of the system.
There was also a subtle issue with extended bytecodes. Many Smalltalk-80 bytecode instructions have a “short” form that encodes a small operand directly in the opcode byte, and an “extended” form that uses a second byte for larger operands. The compiler has to choose the right form based on the operand’s value, and the boundary conditions differ between instruction types. One category (extended stores) had the threshold wrong, which caused methods with more than a certain number of local variables to emit incorrect store instructions.
These were found and fixed before the interpreter was written. The value of having a test suite for compiler output — independent of any interpreter — is that these bugs could be isolated and verified without the additional noise of an interpreter that might also have bugs.
The Global Init Expressions
The source file contains something beyond class definitions: several hundred free-standing expressions, scattered throughout, that a running Smalltalk-80 system would execute immediately as it encountered them during file-in. These are initialization expressions: setting up class variables, registering classes in dictionaries, configuring global state.
Some examples of what these do: Smalltalk at: #Processor put: ProcessorScheduler new creates the process scheduler singleton and installs it in the global dictionary. TextConstants := Dictionary new creates a pool dictionary that the Text class references. SoundRecorder initialize triggers a class-side initialization method.
These expressions are not method definitions. They’re imperative statements that assume a running Smalltalk environment. In a normal file-in operation on a live system, they execute as they’re encountered, and by the time the file-in is complete, the system is in the right state.
I chose to compile these into the JSON alongside the class definitions, preserving them in source order. At the end of cold start — after the heap is built — they can be converted into Smalltalk doIt expressions and executed by the interpreter. This was a VM validation mechanism: executing real Smalltalk code against a freshly-built heap would exercise the interpreter, method dispatch, primitive operations, and global variable access all at once. It turned out to be exactly the right idea — and considerably more painful than expected. The problems it uncovered are the subject of Part 5.
Where Things Stand at the End of Part 2
By August 2025 I had a Smalltalk-80 compiler that:
- Correctly parsed all 41,400 lines of the Smalltalk-80 system source, using a grammar discovered empirically from the source itself
- Produced a JSON intermediate representation capturing complete structural information for every class, including compiled bytecode for every method
- Handled all metaclass relationships correctly, distinguishing class-side from instance-side method definitions
- Compiled global init expressions and preserved them in the output
- Had a test suite validating bytecode output for all major instruction categories
What I didn’t have was anything that could execute any of it. That’s Part 3.